 MONDAY: Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
MONDAY: Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
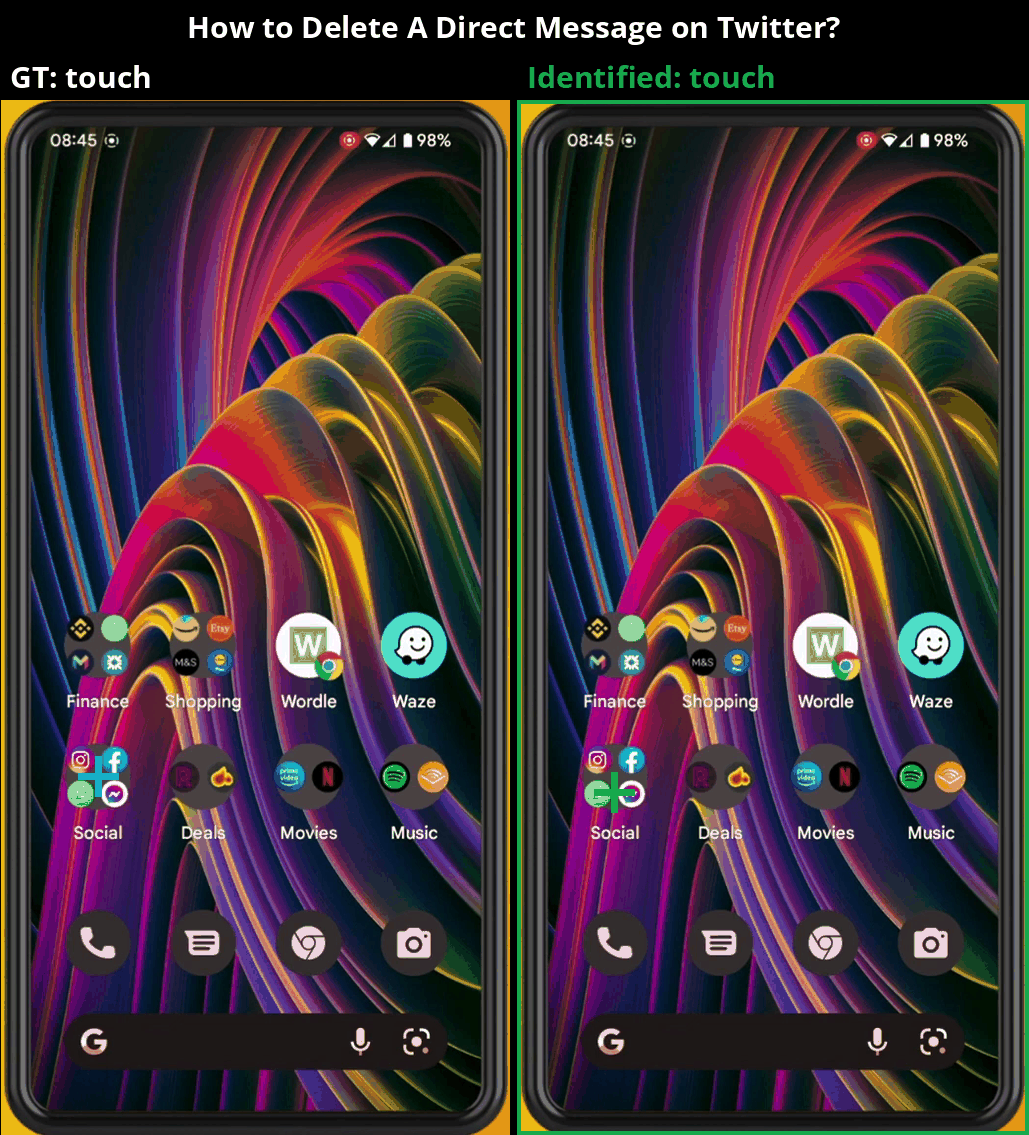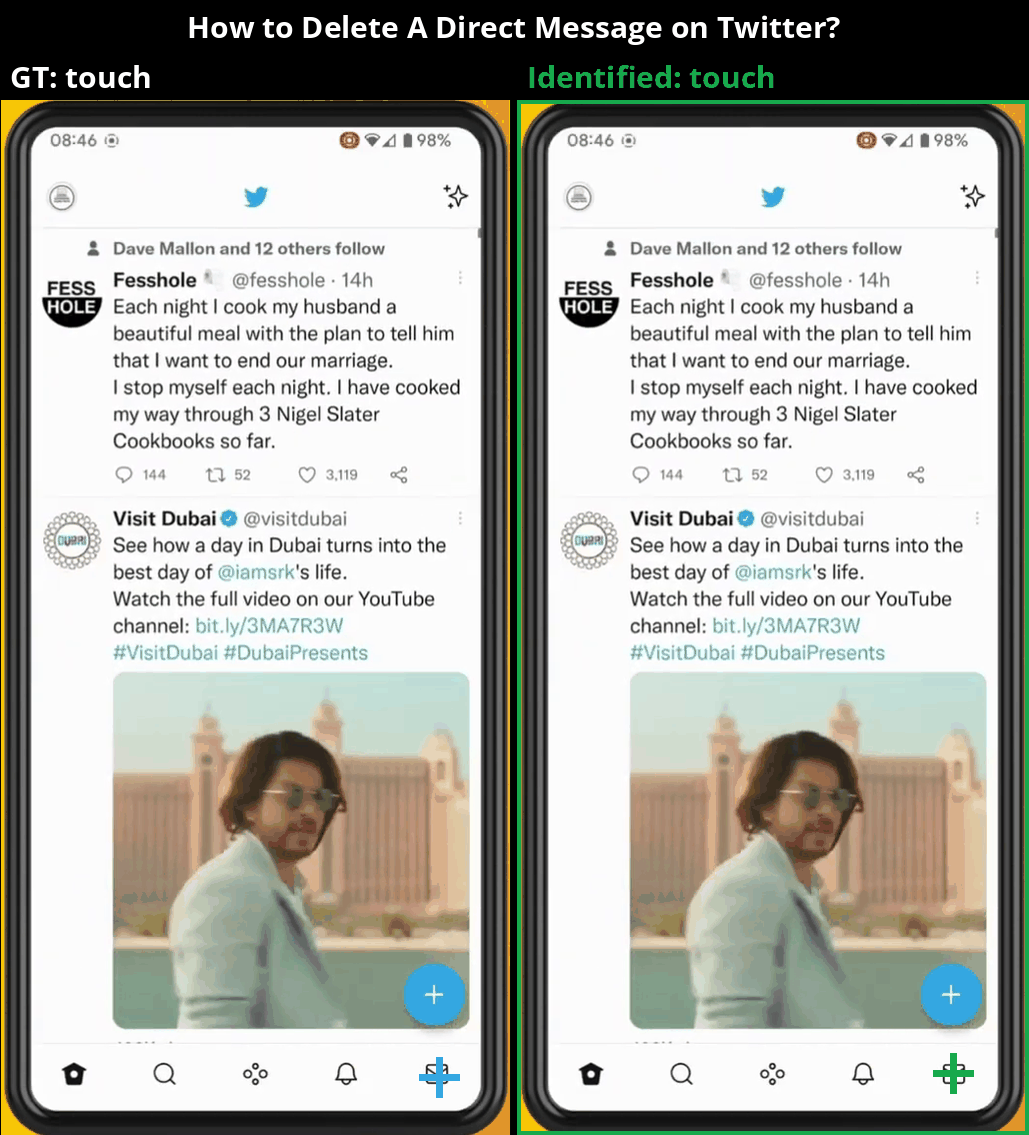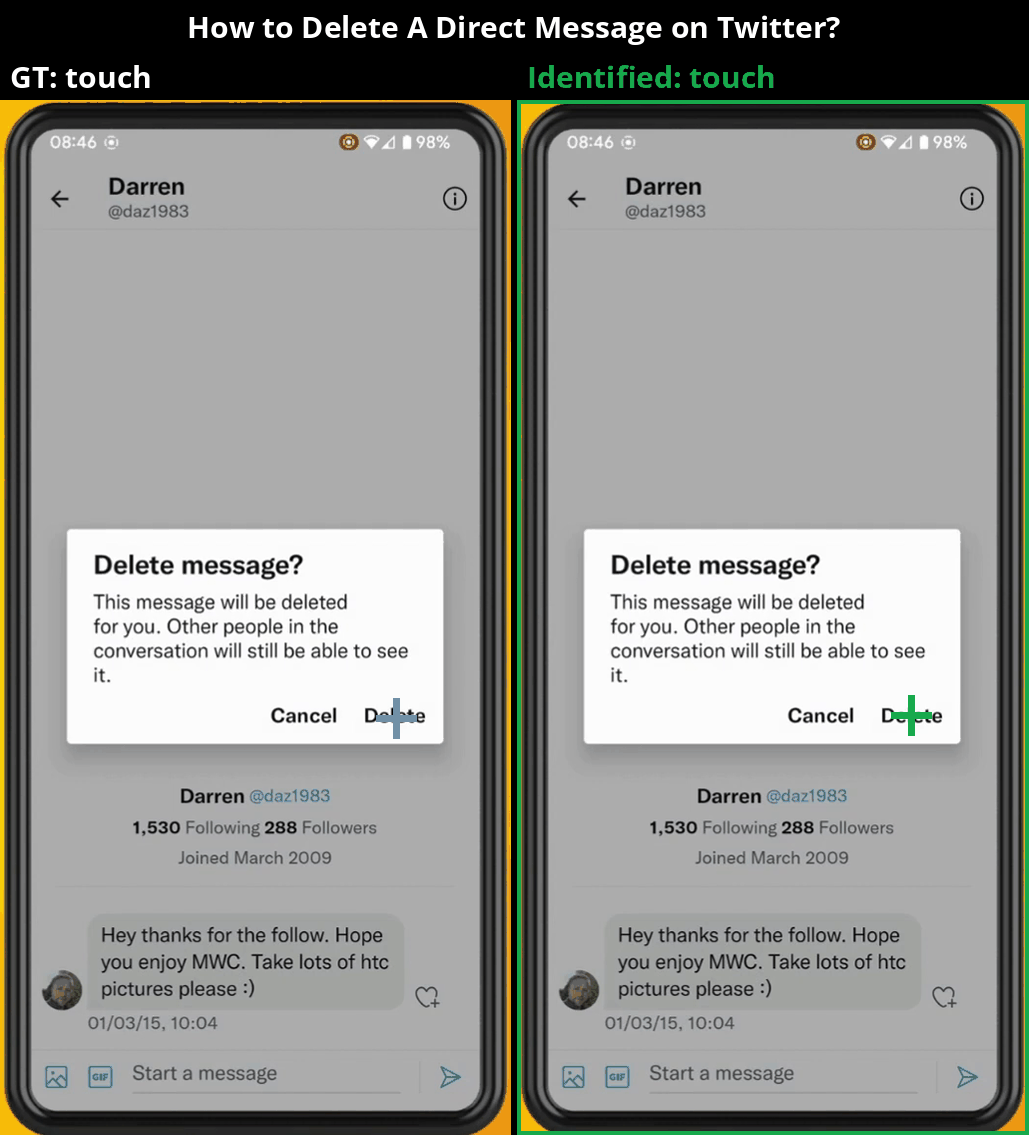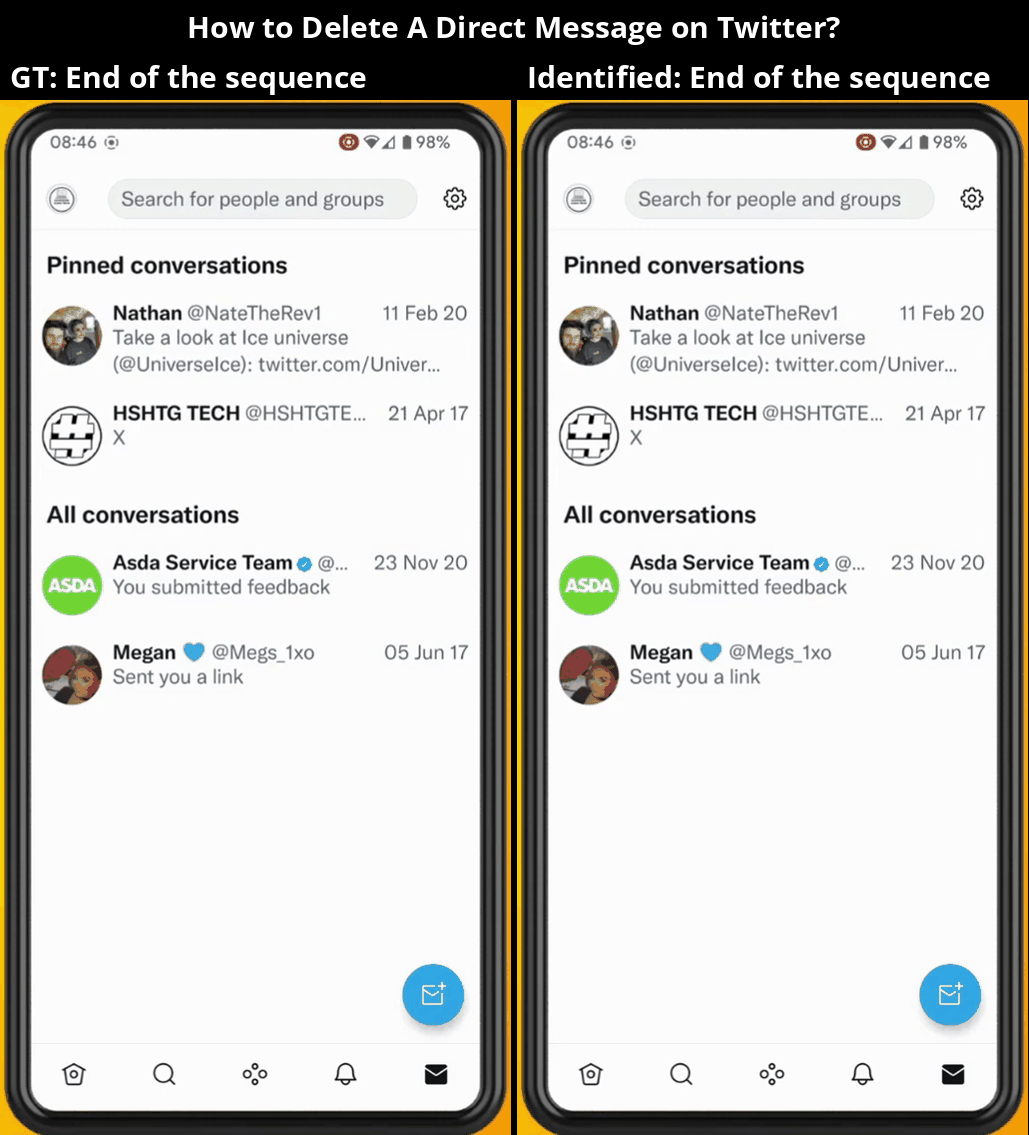
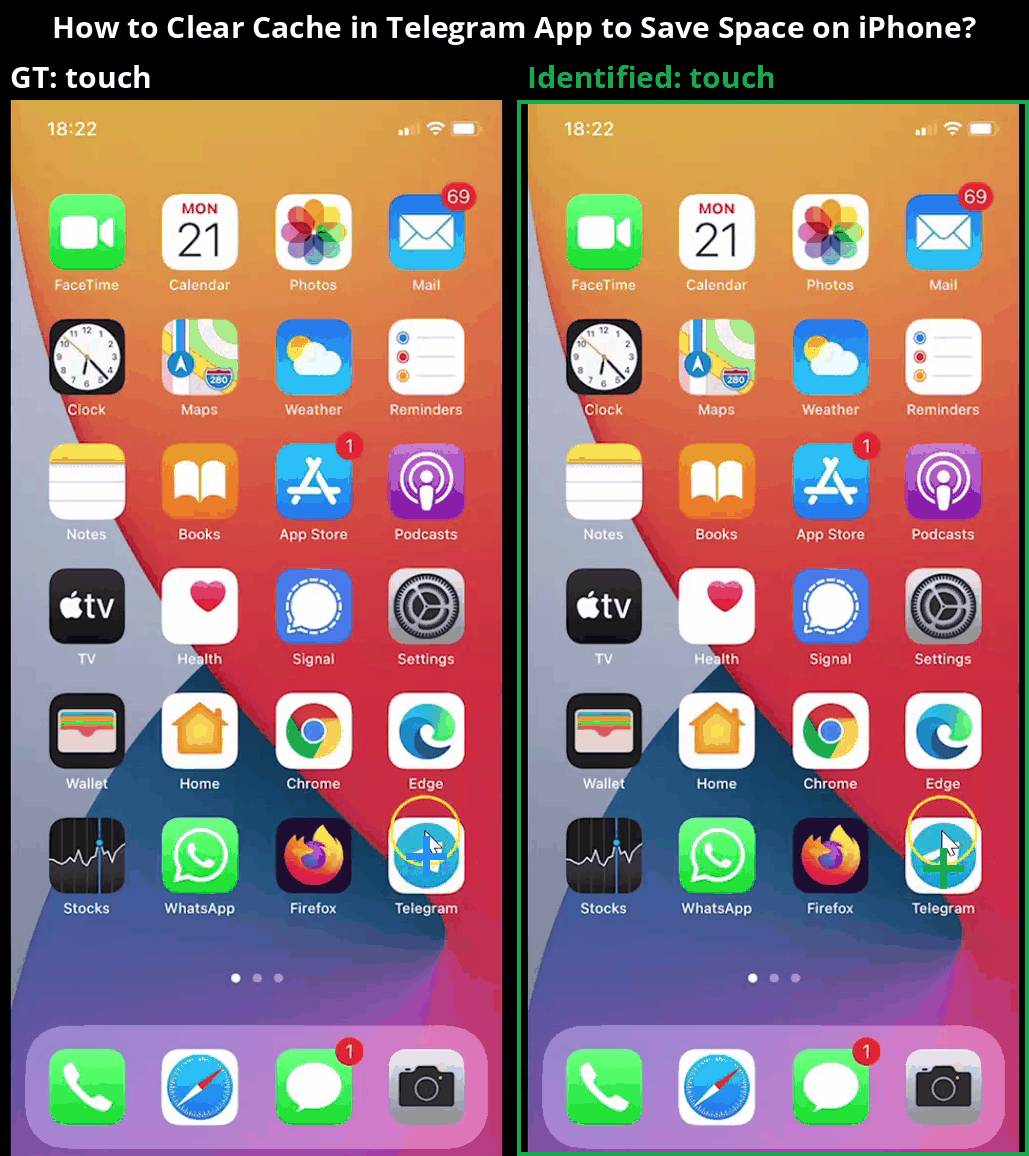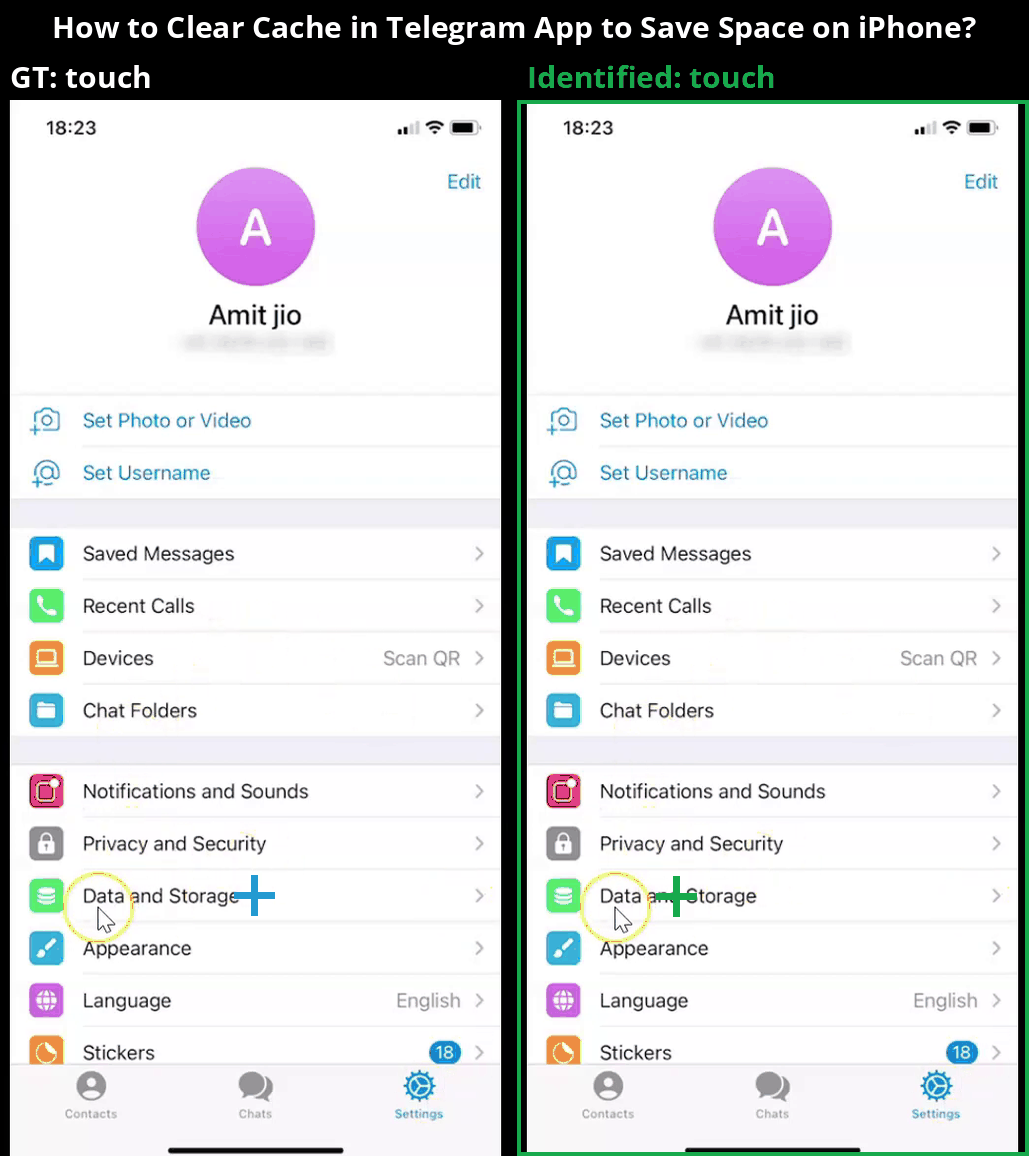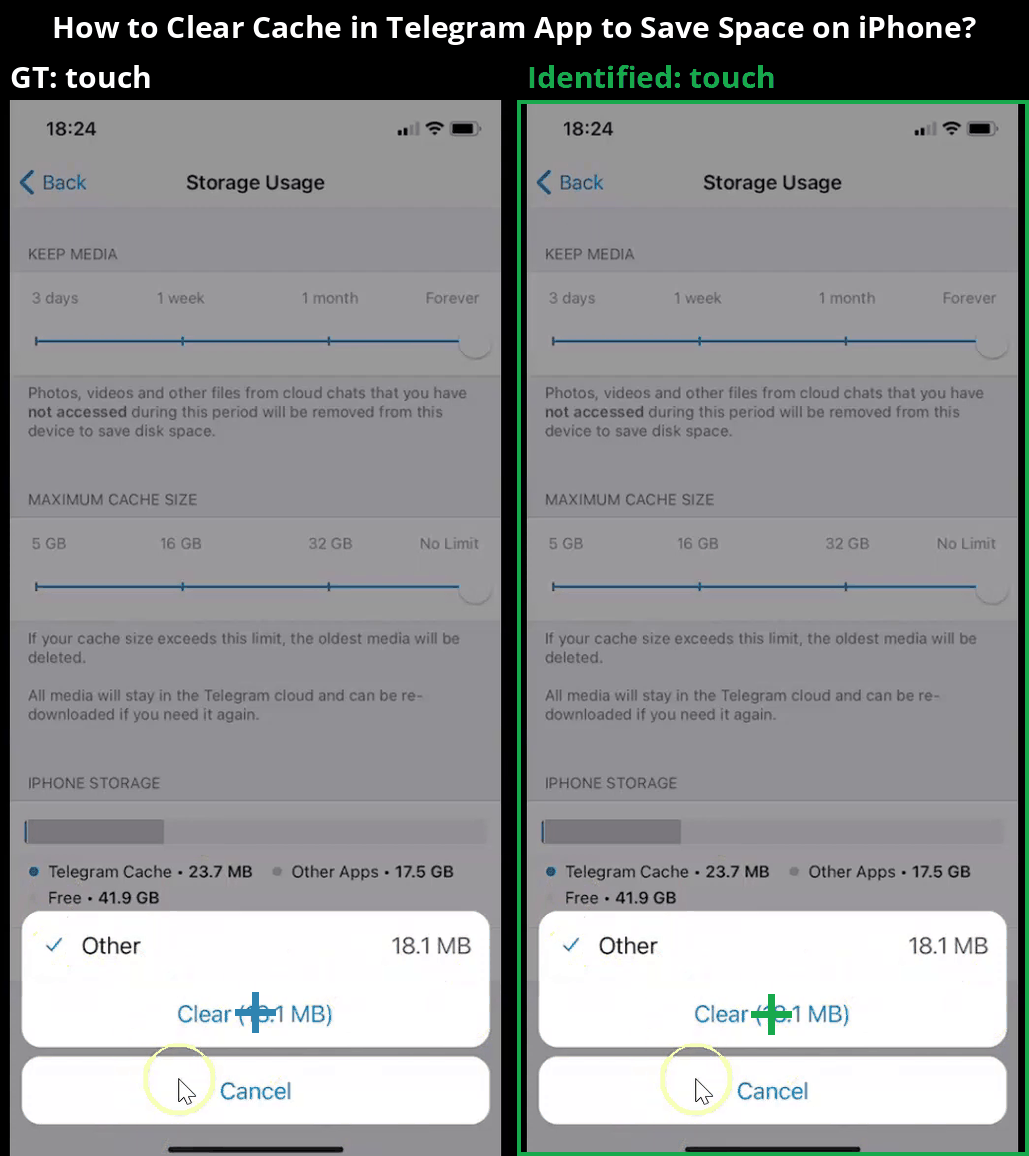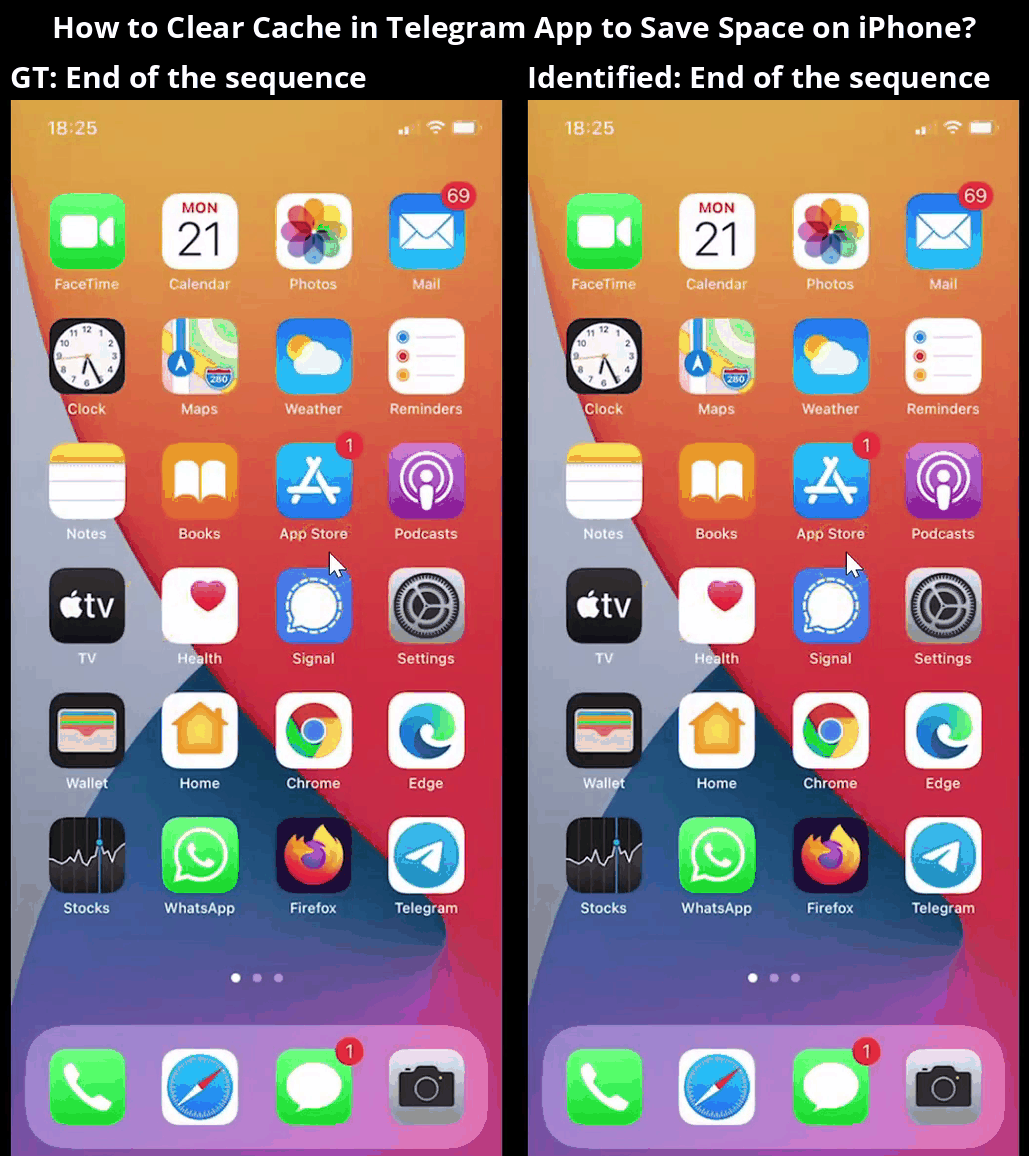
Overview
MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube) is a cross-platform dataset for training vision-language navigation agents on real-world mobile interfaces. We tackle key challenges in building robust GUI agents by collecting diverse, realistic data at scale—without requiring direct access to the environments.
Our data is collected from publicly available YouTube videos using a robust, fully-automated pipeline that ensures high quality across various mobile OS platforms (Android and iOS), OS versions, and user configurations.
MONDAY is:
- Diverse: Covers both Android and iOS with data from 2,479 apps, including system apps and a wide range of GUI configurations.
- Large-Scale: Includes 20,320 sequences and 312,754 annotated frames.
- Real-World: Tasks curated from CommonCrawl web posts (e.g., C4, Dolma datasets) and videos sourced from YouTube capture authentic, real-world mobile interactions.
In contrast to traditional emulator-based data collection methods, MONDAY introduces a new paradigm in GUI agents: collecting human demonstration from videos, with zero access to the GUI systems. Models trained on our dataset demonstrate strong generalization on both public and out-of-distribution datasets—highlighting the effectiveness and value of this approach.
Data Collection

Core components of the MONDAY data collection framework, showing scene transition detection followed by a 3-step action identification process.
Our data collection framework consists of several carefully designed stages to extract high-quality mobile OS navigation data from real-world videos. The process includes these key steps:
- Mobile Navigation Video Collection: We gather real-world instructional videos from YouTube based on user-written task queries mined from CommonCrawl web posts (e.g., C4, Dolma datasets). Videos are filtered to include only mobile phone content, with clean views and narration.
- Scene Transition Detection: We isolate phone screens and detect transitions using OCR-based text change analysis, ensuring robust segmentation of task steps across varying UI layouts.
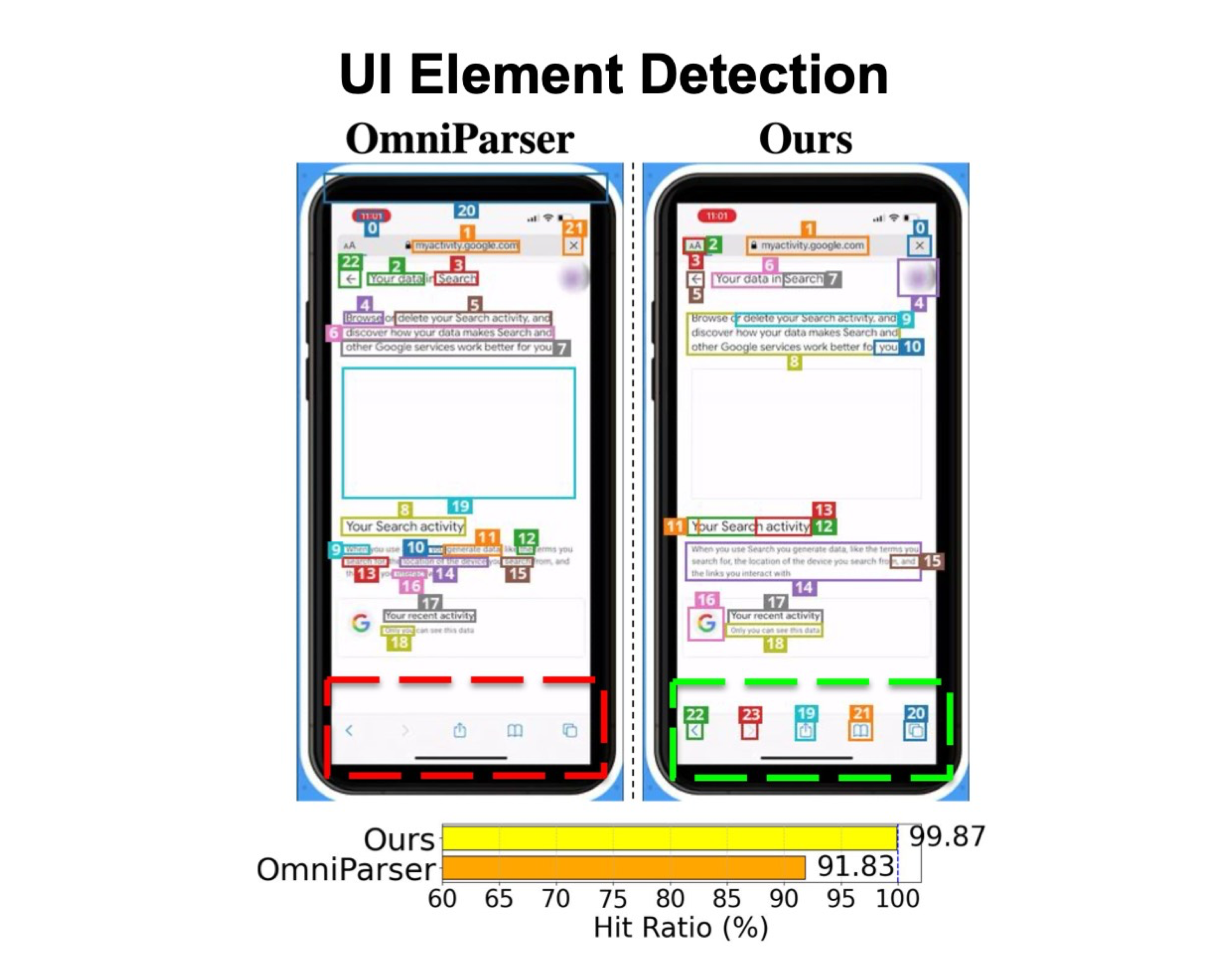
- UI Element Detection: Detected screens undergo UI element extraction using GroundingDINO and PaddleOCR, followed by heuristic filtering to identify actionable elements.
- 3-step Action Identification: Actions are annotated using a novel three-step method: (1) summarizing scenes, (2) initial action prediction using Set-of-Marks (SoM), and (3) refined action localization with zoomed-in views.
Dataset Statistics
Below are tables and figures presenting some statistics of MONDAY:
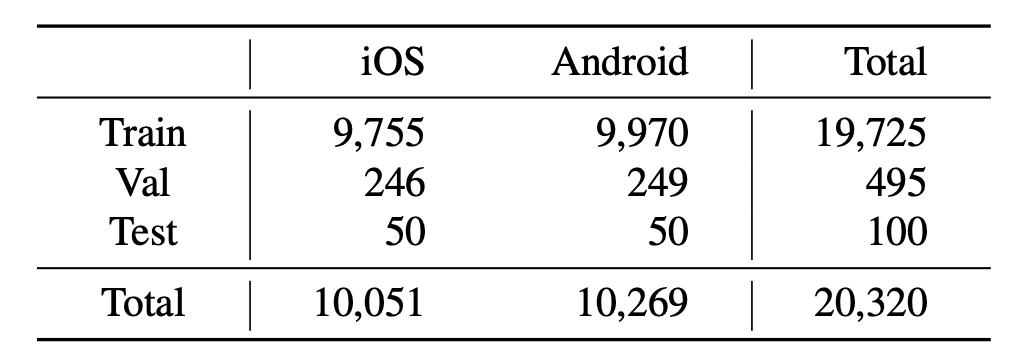
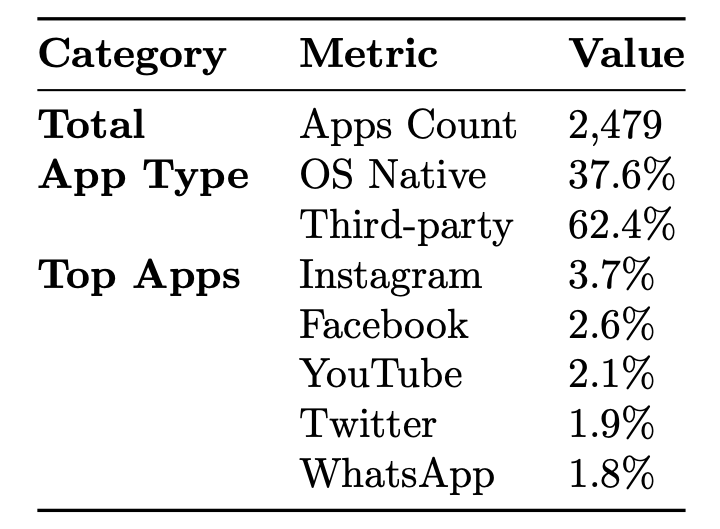
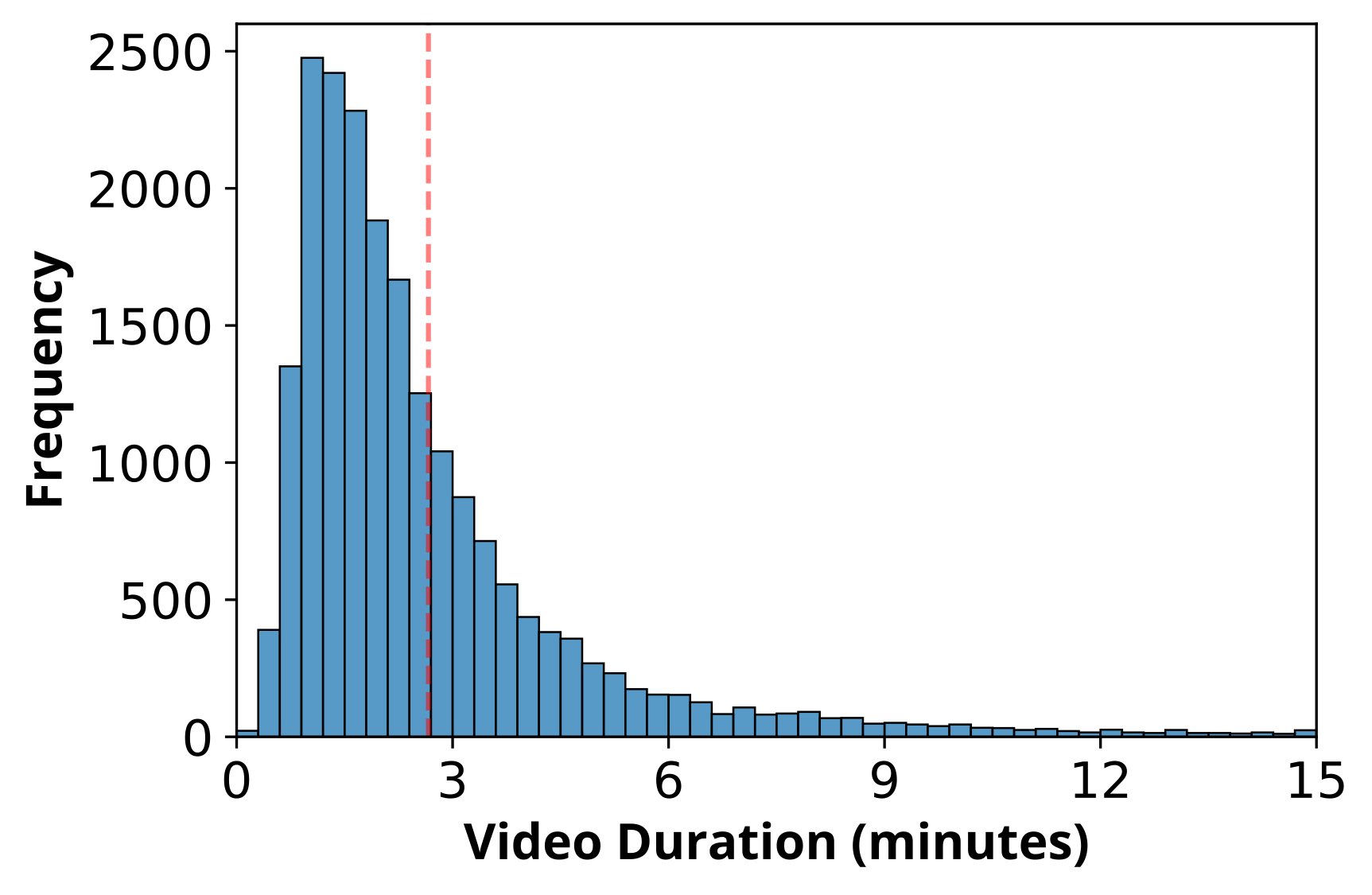
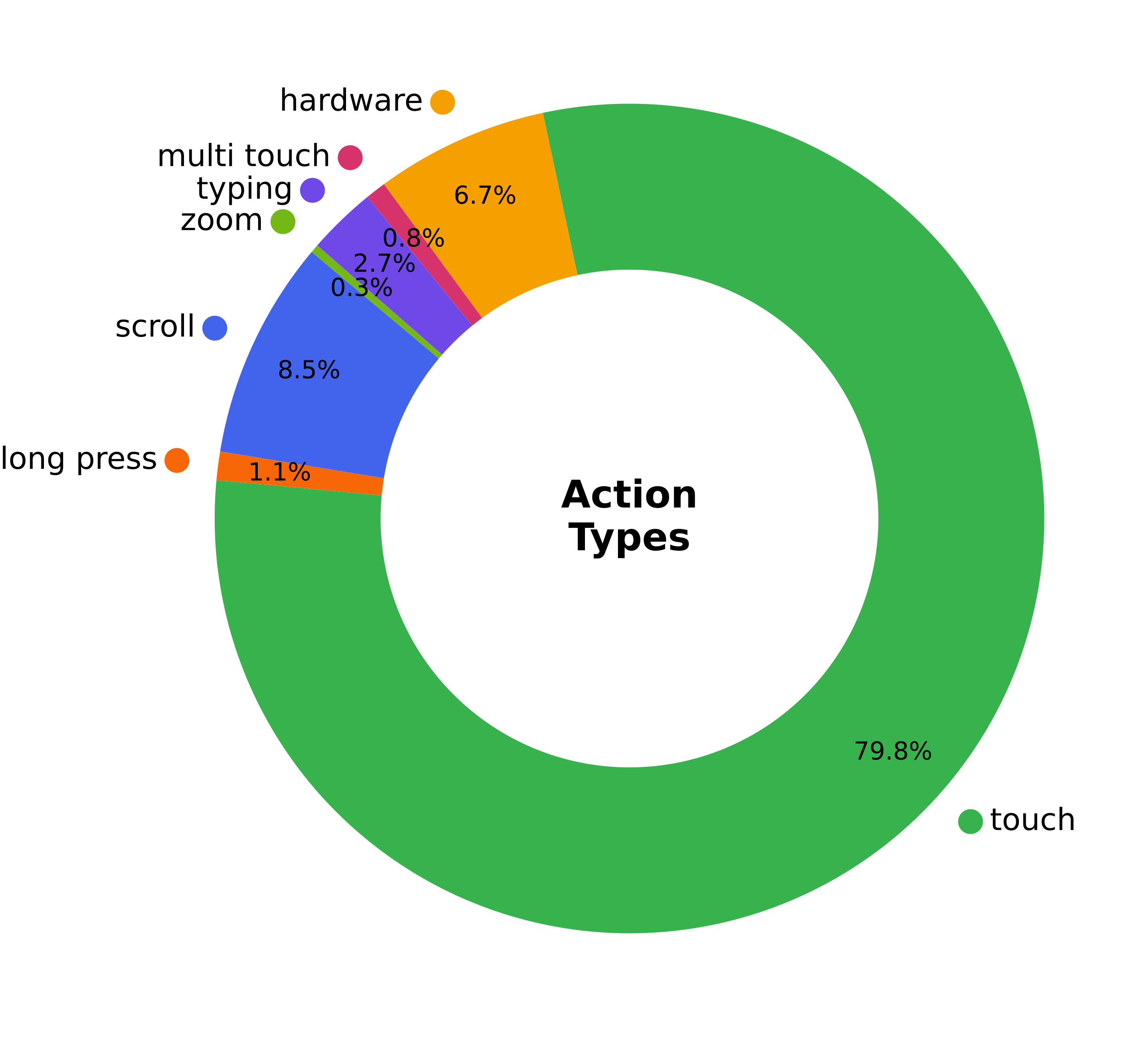
(Top-Left) Number of videos across different splits. MONDAY maintains approximately a 50:50 ratio of iOS to Android videos in each split.
(Top-Right) App statistics in MONDAY videos. MONDAY includes both native OS system apps and third-party apps.
(Bottom-Left) Distribution of video duration in minutes. Red vertical dotted line stands for the average duration of 2.66 minutes.
(Bottom-Right) Action type distribution. Touch actions dominate at 79.83%, followed by scroll (8.53%) and other actions.
Experiments and Results
We evaluate both our dataset collection method and models trained on MONDAY through comprehensive experiments. To evaluate our data collection method, we manually annotated 100 videos.Dataset Collection Method Evaluation
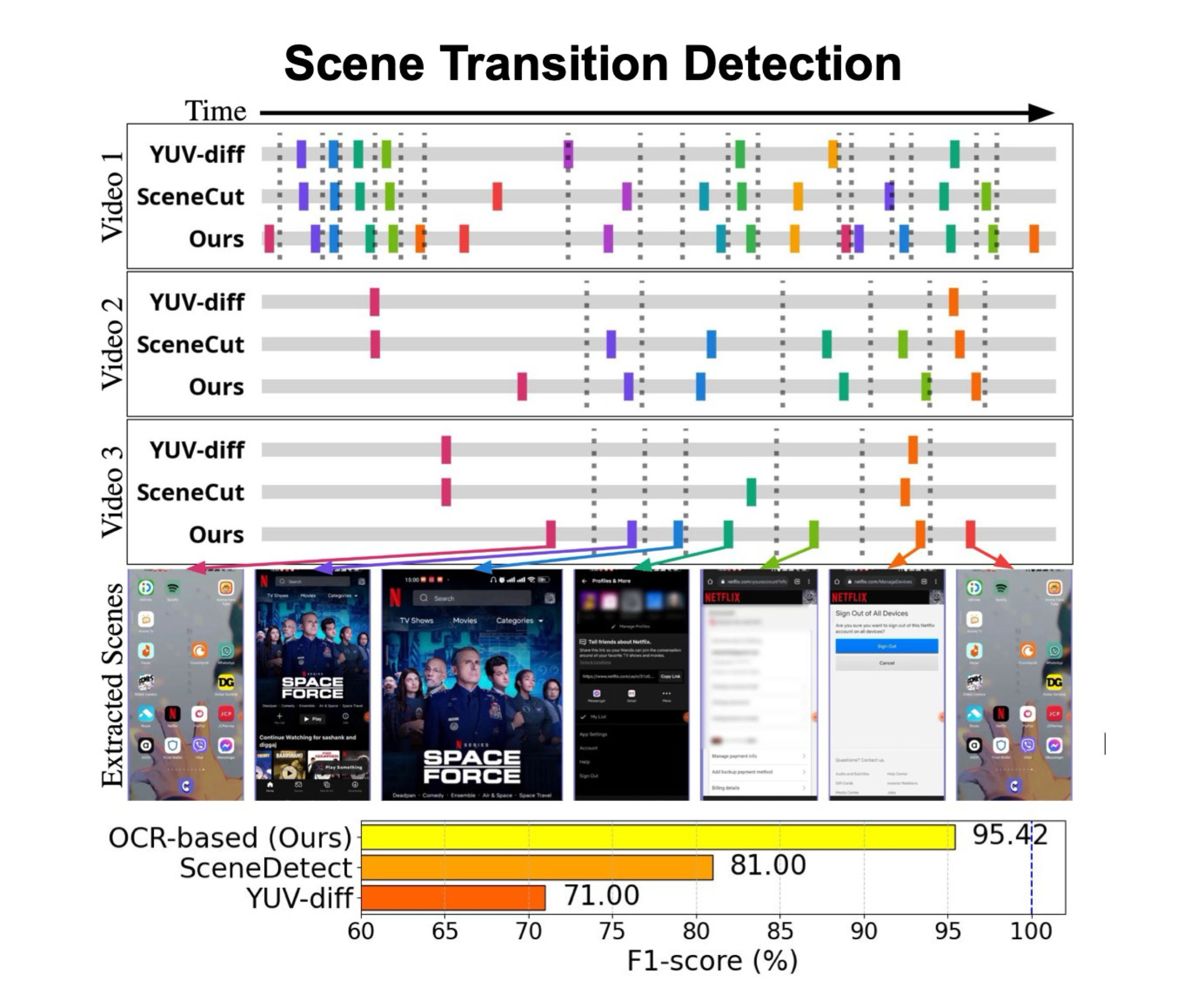

(Left) Our OCR-based approach significantly outperforms baselines by leveraging text content changes rather than traditional visual features.
(Middle) Our UI element detection is robust, accurately identifying home screen icons and bottom-positioned UI elements that OmniParser frequently misses.
(Right) Our multi-image 3-step approach outperforms simplified variants.
Mobile Navigation Agent Evaluation
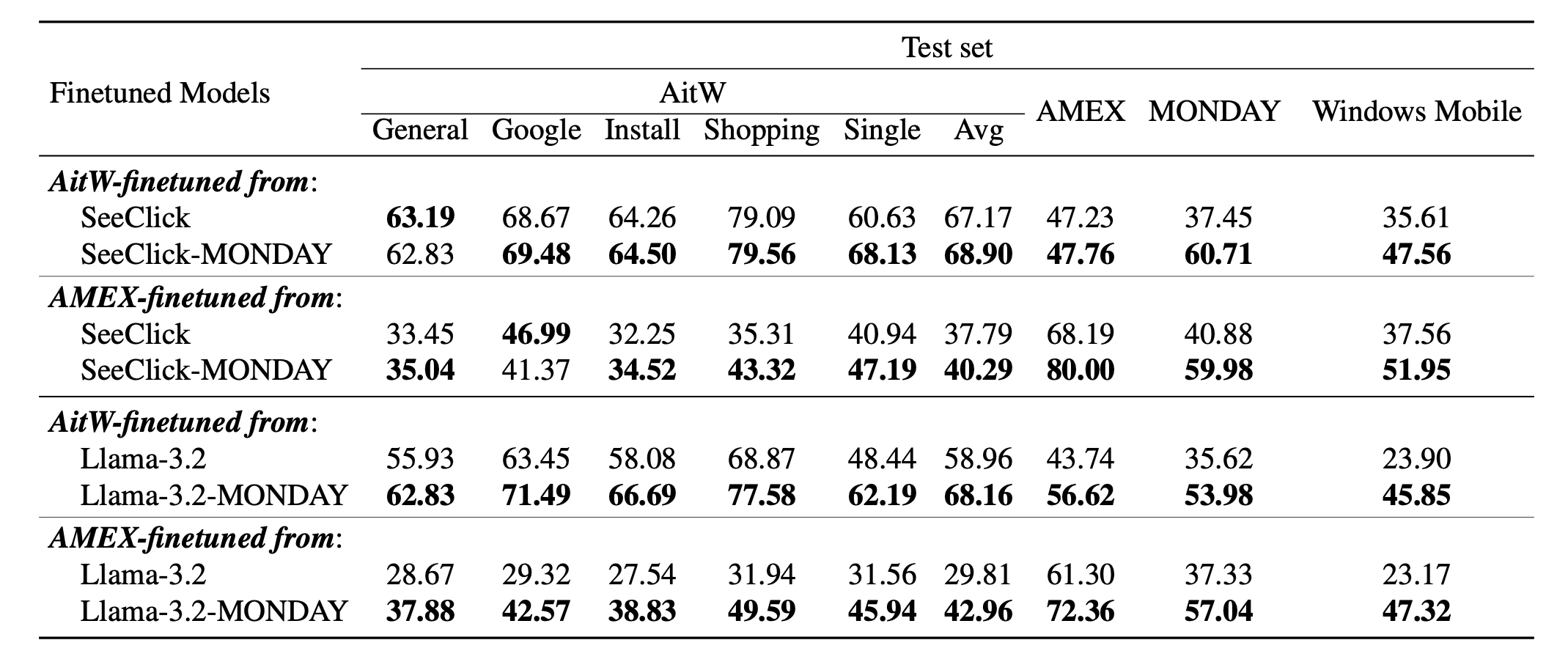
Step accuracies of the original pre-trained models (SeeClick, Llama-3.2) vs. the corresponding MONDAY-induced variants (SeeClick-MONDAY, Llama-3.2-MONDAY). Models finetuned from MONDAY-induced variants mostly outperform the baselines and generalize well to an unseen mobile platform (Windows Mobile).
Download and Usage
You can download our dataset from Hugging Face:
from datasets import load_dataset
dataset_dict = load_dataset("runamu/MONDAY")
To learn how to use the dataset, check out our code repository on GitHub.
For detailed information about the dataset fields, visit the dataset card on Hugging Face.
Citation
@inproceedings{jang2025_monday,
title={{Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents}},
author={Jang, Yunseok and Song, Yeda and Sohn, Sungryull and Logeswaran, Lajanugen and Luo, Tiange and Kim, Dong-Ki and Bae, Kyunghoon and Lee, Honglak},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}